
先日、Hugging Faceからevaluateという新しいライブラリがリリースされました。何を目的としているのか・どんなことができるのかなどが気になったため、調べてみました。
以下の内容は、公式ドキュメントやRelease notes、上のツイートのスレッドを参考にしています。
リリースした目的とは?
Release notesによると、以下の5つを目的としているようです。
- reproducibility:共通の評価方法を確立することで、結果の報告や再現を容易にする
- ease-of-use:同じインターフェースで様々な評価ができる
- diversity:評価指標、比較、測定といった幅広い評価が可能なツールである
- multimodal:マルチモーダルにモデルやデータセットを評価できる
- community-driven:Hugging Face Hubを通じて、誰でも評価指標を追加できる
具体的には何ができるのか?
予測結果の評価ができる
まず、evaluateというライブラリ名の通り、評価指標による評価ができます。これは、従来だとscikit-learnなどが担っていた機能ではないでしょうか。
例えば、accuracyであれば、以下のように計算することが可能です。
# evaluateによる評価
import evaluate
# 公開されている"accuracy"をloadする
# https://huggingface.co/spaces/evaluate-metric/accuracy
# ちなみに、実装はscikit-learnのものをそのまま使っています
metric = evaluate.load("accuracy")
# 予測値をpredictionsに、答えをreferencesに渡すことで計算可能
metric.compute(predictions=[0, 1], references=[1, 1])
# >>> {"accuracy": 0.5}
# scikit-learnによる評価
from sklearn.metrics import accuracy_score
# 予測値をy_predに、答えをy_trueに渡すことで計算可能
accuracy_score(y_true=[1, 1], y_pred=[0, 1])
# >>> 0.5使用可能な評価指標の一覧は https://huggingface.co/evaluate-metric で確認できるようです。上のツイートの添付画像からもわかるように、対象としている評価指標はNLPに関するものだけでなく画像や強化学習のものも含まれています。
また、BLEUやGLEUなどのタスクに対する評価も用意されているため、論文などで結果を報告する際に便利かもしれません。
# 使用可能な評価指標はライブラリからも取得可能
# https://huggingface.co/docs/evaluate/v0.1.0/en/package_reference/loading_methods#evaluate.list_evaluation_modules
evaluate.list_evaluation_modules(
module_type="metric",
include_community=False,
with_details=True
)さらに、公開されている評価指標に使いたいものが存在しない場合は、Hugging Face Hubを通じて追加することが可能です。今回は、公式ドキュメントを参考にしつつ、Hugging Face Hub上にSpaceを作成するところまでやってみました。これであとは、作成したSpaceにスクリプトを追加するだけで良い状態になるはずです。
Hugging Face Hubを利用するためには、アカウントが必要なので、お持ちでない方はこちらから作成してください。アカウントが作成できたら、今回はCLIから作業を行うため、アクセストークンを準備します。右上のアイコンをクリックして、Settings -> Access Tokensからwrite権限を持ったトークンを作成してください。
作成したトークンをコピーしたら、以下のコマンドを実行してみてください。
# Hugging Face CLIへのログイン
# トークンを要求されるので、先ほどコピーしたものを貼り付ける
huggingface-cli login
# "My metricという追加したい評価指標用のSpaceを作成する
evaluate-cli create "My Metric"すると、自分のHugging Faceのプロフィールページに以下のようにスペースが作成されていると思います。
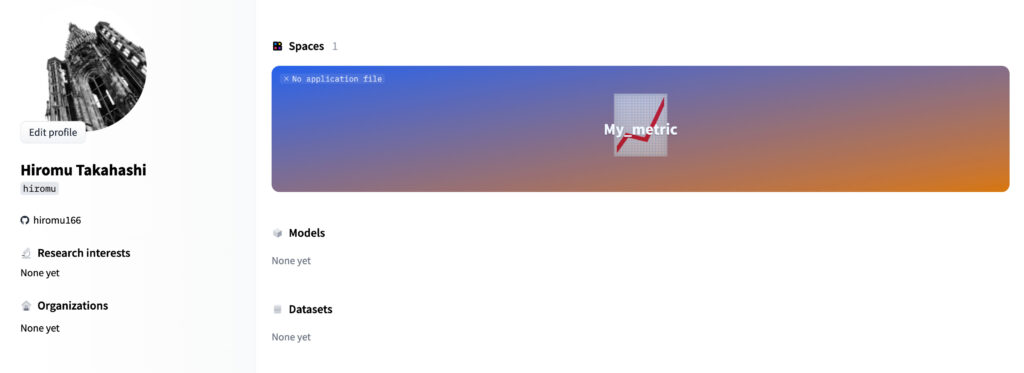
あとは、公式ドキュメントやAccuracyのページを参考にしながら、必要なファイルを作成すれば作業完了だと思います。(自分はもう少しライブラリが安定したら、試してみようと思います。。)
余談:AccuracyのページにAppというセクションがあり、gradioを使ってページ上で評価指標のデモが表示できているのがなかなかいいなと思いました。gradioはstreamlitみたいなものかなというイメージなのですが、なかなか面白そうなので、近々記事にしたいと思っています。
予測結果の比較ができる
ここで紹介する結果の比較というのは、複数のモデルのAccuracyを単純に比較するというイメージではありません。イメージとしては、評価指標の結果を比較するというよりは、複数の予測があった時にその結果を比較して算出する評価指標が計算できるというものです。現時点では、Exact Matchとマクネマー検定が用意されています。(https://huggingface.co/evaluate-comparisonで確認できます。)
# Exact Matchの計算
import evaluate
# 公開されている"exact_match"をloadする
# 今回は比較なので、module_typeは"comparison"を指定
metric = evaluate.load("exact_match", module_type="comparison")
# 1つ目の予測値をpredictions1に、2つ目の予測値をpredictions2に渡すことで計算可能
metric.compute(predictions1=[0, 1, 1], predictions2=[1, 1, 1])
# >>> {'exact_match': 0.6666666666666666}データセットに対する測定ができる
測定というのは、文章に重複があるか・単語数はどれくらいかなどをデータセットに対して計算したり、学習したモデルを用いてPerplexityを計算することを意味しています。現状の機能はまだまだ少ないですが、Perplexityを以下のように簡単に計算できるというのは、なかなか良さそうだと思いました。(https://huggingface.co/evaluate-measurementで確認できます。)
# GPT-2を用いたPerplexityの計算
import evaluate
# 公開されている"perplexity"をloadする
# 公式のサンプルコードでは、測定なのでmodule_type="measurement"としていたが、なぜかエラーが出たので外した
metric = evaluate.load("perplexity")
# Perplexityを計算したい文章を用意
input_texts = ["lorem ipsum", "Happy Birthday!", "Bienvenue"]
# GPT-2を用いて計算
results = metric.compute(
model_id='gpt2',
input_texts=input_texts
)
# 結果の確認
print(list(results.keys()))
# >>> ['perplexities', 'mean_perplexity']
# 全ての文章の平均を表示
print(round(results["mean_perplexity"], 2))
# >>> 22.87
# "lorem ipsum"に対する結果を表示
print(round(results["perplexities"][0], 2))
# >>> 8.18どんな使い方ができそうか
最後に、現時点でどんな使い方ができそうかについて、公式から発表されているものと自分の考えを紹介しようと思います。
Hugging Faceのパイプラインと組み合わせて使う
文章分類のパイプラインをevaluateと組み合わせることで、これだけのコードでデータセットに対する評価ができるとのことです。さらに、ブートストラップサンプリングを行って、サンプルによってどれくらい評価結果がブレうるのかを確認できるのは、かなり便利だと思いました。
実験結果の保存
実験に使ったパラメータとともに結果を保存したり、その結果をHugging Face Hubに公開しているモデルのページに追加したりすることもできるようです。
コンペティションのメトリック共有
上で紹介したように、作成した評価指標を公開することが可能です。この機能を利用して、kaggleなどのコンペティションで独自のメトリックを作成したら、それをコードとして使い回すのではなく、evaluateを通してどこからでもダウンロードできるようにするというのもアリなのかなと思いました。
おわりに
今回は、Hugging Faceから新たにリリースされたevaluateというライブラリを紹介してみました。まだまだ機能は少ないですが、これからどのように発展していくか楽しみです。自分も機会があれば、指標の追加などで貢献していきたいです。
最後まで、ご覧いただきありがとうございました。


コメント