
先日、Twitterでtransformersとscikit-learnをscikit-learnのPipelineを使って組み合わせることができることを知りました。
構成としては、transformersのモデルの最終層のアウトプットを特徴量としてscikit-learnのモデルに渡すというよくあるパターンだと思うのですが、transformersのモデルから出力を得るところで使用されているwhatliesというライブラリがかなり便利だと思ったので紹介します。
whatliesとは?
whatliesは、”What lies in word embeddings?”というコンセプトで作成されており、単語埋め込みに関するライブラリです。
GitHubのスター数は、執筆時点では371でそれほど知名度が高いわけではないですが、単語埋め込みは扱うことが多いので、活用方法を知っておいて損はないと思い、調べてみました。
GitHub

公式ドキュメント

何ができるのか
ここからは、このライブラリで具体的に何ができるのかについて、簡単に紹介します。
できることは大きく分けると2つで、単語埋め込みをインタラクティブ形式で可視化できること、そして先ほど少し言及した、様々なモデルの単語埋め込みを簡単にscikit-learnのモデルの特徴量として使えることです。
単語埋め込みをインタラクティブ形式で可視化できる
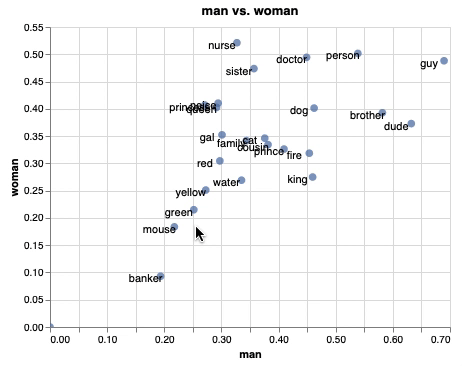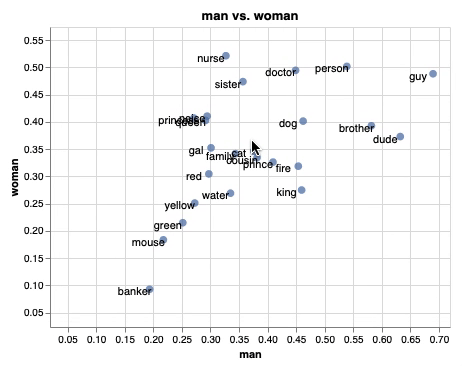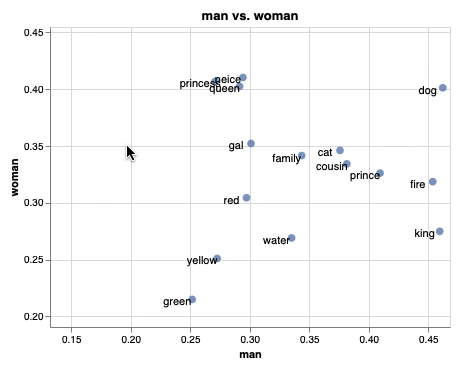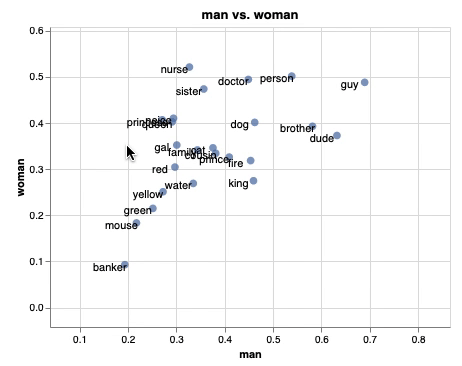
単語埋め込みを平面にプロットして、インタラクティブに操作することができます。plotlyを使うことでも、同じようなことが実現できますが、emb.plot_interactive() を使うだけで簡単に実現できるのが魅力の1つだと思います。また、上のgifはそれぞれの単語をx軸を”man”、y軸を”woman”として関係性をプロットしていて、少し凝ったこともできるようになっています。
scikit-learnのモデルの特徴量として使える
transformers以外にも、有名どころだとspaCyやGensimのモデルなども扱うことが可能です。現時点では、下記のモデルに対応しているようです。
- spaCy
- Sense2Vec
- floret
- fasttext
- CountVector
- TFIDFVector
- BytePair
- ConveRT
- Gensim
- HuggingFace
- LaBSE
- TFHub
- USE
- Sent TFM
使い方
実際に動かしてみます。使用したnotebookはこちらから確認いただけます。

インストール方法

# 最小限の機能
pip install whatlies
# spacyやtransformersのモデルを扱いたい場合
pip install whatlies[spacy]
pip install whatlies[transformers]
# 全部盛り
pip install whatlies[all]単語埋め込みを可視化する


今回は、使用する機会が多いGensimのword2vecを使用します。
from whatlies.language import GensimLanguage
# GensimLanguageはkv形式のモデルしか対応していない点に注意
model = GensimLanguage('/path/to/xxxxx.kv')矢印で可視化
model['man'].plot(kind="arrow", color="blue")
model['woman'].plot(kind="arrow", color="red")
model['king'].plot(kind="arrow", color="blue")
model['queen'].plot(kind="arrow", color="red")
plt.axis('off')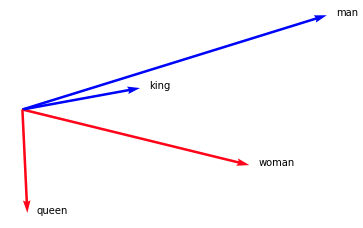
model['man'].plot(kind="arrow", color="blue")
model['woman'].plot(kind="arrow", color="red")
model['king'].plot(kind="arrow", color="blue")
model['queen'].plot(kind="arrow", color="red")
(model['king'] - model['man'] + model['woman']).plot(kind="arrow", color="pink")
plt.axis('off')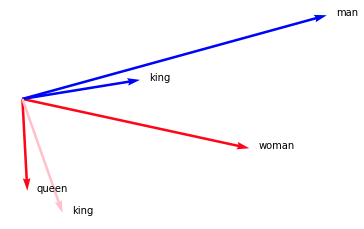
このように、ベクトルの足し引きの結果を表示することも可能です。king – man + womanがqueenのベクトルと近いことが確認できます。
散布図で可視化
GitHubのREADMEに掲載されていたgifは以下のコードで再現できます。
# 可視化したい単語を指定
words = ["prince", "princess", "nurse", "doctor", "banker", "man", "woman",
"cousin", "neice", "king", "queen", "dude", "guy", "gal", "fire",
"dog", "cat", "mouse", "red", "blue", "green", "yellow", "water",
"person", "family", "brother", "sister"]
# 単語埋め込みを取得
emb = model[words]
# 可視化(x軸をman, y軸をwoman)
emb.plot_interactive('man', 'woman')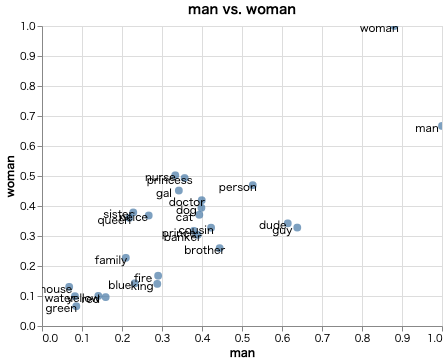
次元を指定してプロットすることも可能です。
# 可視化(x軸を次元0, y軸を次元1)
emb.plot_interactive(x_axis=0, y_axis=1)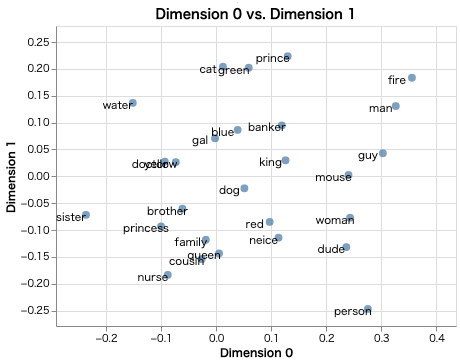
PCAやUMAP、t-SNEを使用して次元削減したものを可視化することも簡単にできます。
from whatlies.transformers import Pca, Umap
pca_emb = emb.transform(Pca(2))
umap_emb = emb.transform(Umap(2))
plot_pca = pca_emb.plot_interactive()
plot_umap = umap_emb.plot_interactive()
plot_pca | plot_umap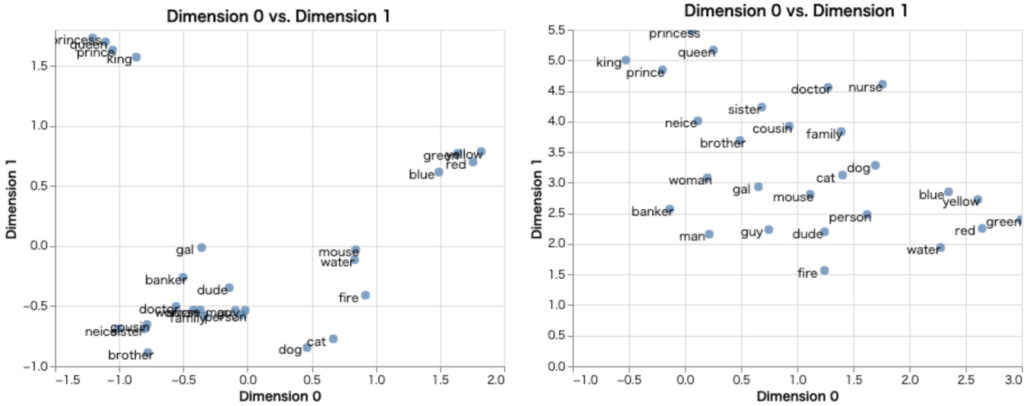
ヒートマップで可視化
単語埋め込みのコサイン類似度をヒートマップで可視化する機能もあります。
# metricは'cosine'と'correlation'が選択可能
emb.plot_similarity(metric="cosine")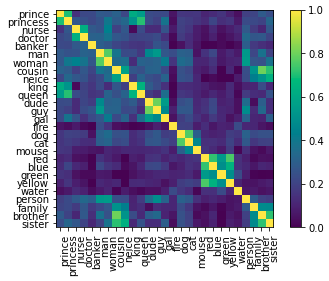
scikit-learnのモデルに特徴量として使う

今回は、Hugging Face datasetsを使ってIMDbデータセットをダウンロードして学習と推論を行ってみます。
# IMDbデータセットの準備
import datasets
import pandas as pd
imdb = datasets.load_dataset('imdb')
train_df = pd.DataFrame(imdb['train'])
test_df = pd.DataFrame(imdb['test'])これでデータセットが準備できたので、先ほど用意したword2vecのモデルとLGBMClassifierを使って学習してみましょう。
from sklearn.pipeline import Pipeline
from whatlies.language import GensimLanguage
from lightgbm import LGBMClassifier
# pipelineを作成
pipe = Pipeline([
("embed", GensimLanguage('/path/to/xxxxx.kv')),
("model", LGBMClassifier())
])
# 学習
pipe.fit(train_df['text'].tolist(), train_df['label'].tolist())推論を行い、精度を確認しましょう。
# 推論
test_pred = pipe.predict(test_df['text'].tolist())
# 精度の確認
from sklearn.metrics import classification_report
print(classification_report(test_df['label'].values, test_pred))今回は、word2vec + LGBMでしたが、参考にした以下のnotebookのようにtransformersのモデルを使用することも可能です。

おわりに
今回は、単語埋め込みに関するライブラリであるwhatliesについて紹介しました。インタラクティブに可視化できたり、scikit-learnのPipelineに組み込んで使える点は、実用性がかなりあると思うので、これからお世話になることも多いのではないかと考えています。

コメント